
Par Joel Li, FICA
Président, Commission sur la modélisation prédictive
La science des données a connu un essor formidable au cours de la dernière décennie compte tenu de l’augmentation exponentielle des renseignements qui sont recueillis au sujet de nos habitudes de vie et de l’augmentation de la capacité de traitement.
Les applications et cas d’usage de la science des données sont utiles dans tous les secteurs imaginables et ont eu une incidence indéniable sur les industries et domaines de pratique des actuaires. En raison de cette évolution très rapide, la science des données n’est pas bien définie. Il existe néanmoins des définitions pratiques, comme celle que l’on peut lire sur le site Web de l’IFoA :
La « science des données » est un vaste domaine multidisciplinaire qui a recours à des méthodes scientifiques, processus, algorithmes et systèmes pour extraire des connaissances et des indications à partir de données structurées et non structurées. Elle fait usage de techniques issues de nombreux domaines dans le contexte des mathématiques, statistiques, de l’informatique et de la science de l’information.
À titre de comparaison, selon le site Web de l’ICA :
La science actuarielle est la discipline qui met en application des connaissances spécialisées en mathématique, en statistique et en théorie des risques afin de résoudre les problèmes dans les industries, entre autres, de l’assurance, des finances et de la santé.
La science des données et la science actuarielle sont toutes deux multidisciplinaires; elles tirent des renseignements des données et, pour être fructueuses, nécessitent une compréhension approfondie des processus commerciaux sous-jacents et une excellente connaissance du domaine en question. La science des données se distingue grâce aux nouvelles façons qu’elle offre de résoudre des problèmes d’affaires au moyen d’algorithmes qui étaient auparavant limités par la puissance informatique et à une nouvelle capacité d’exploiter les informations provenant de données non structurées. Autrement dit : Pour résoudre les mêmes problèmes d’affaires, les scientifiques de données ont accès à des outils et à des gadgets plus sophistiqués que ceux qu’offre la science actuarielle, ce qui leur permet d’explorer de nouveaux types de données.
Le champ d’application plus vaste de ces nouvelles approches et méthodes permet à ces scientifiques de pénétrer un plus grand nombre d’industries et de domaines de pratique que les actuaires. En ayant une compréhension plus approfondie de la science des données, les actuaires pourraient tirer profit des résultats de celle-ci dans leur travail et y trouver des applications dans de nouveaux domaines de pratique.
Chevauchements et application
Les mégadonnées et l’analyse prédictive constituent des éléments importants dans le cadre du travail d’un scientifique des données.
Les mégadonnées sont souvent d’abord caractérisées par leur volume, leur vitesse et leur variété.
- Volume : la taille et la quantité des ensembles de données. Bien qu’il n’existe aucun seuil établi pour déterminer qu’il s’agit ou non de mégadonnées, on définit ces dernières comme des ensembles de données dont la taille ne permet pas d’être traitées au moyen de bases de données ou des solutions d’entreposage de données traditionnelles.
- Vitesse : la vitesse à laquelle s’accumulent les mégadonnées. Chaque seconde, des mégadonnées sont produites par des millions d’entités. Les données télématiques provenant des capteurs installés sur les véhicules, les bracelets de suivi de la santé ou les historiques de navigation en sont des exemples courants.
- Variété : la source et la nature hétérogènes des mégadonnées, soit structurées, semi-structurées et non structurées.
Si ces caractéristiques sont utiles et présentent de nouveaux débouchés, il importe également de prendre en considération les défis que posent la véracité et la variabilité associées à l’utilisation des mégadonnées. Il peut être difficile d’apparier, de nettoyer et d’intégrer les mégadonnées à d’autres sources de données. Elles sont aussi très dynamiques et peuvent changer fréquemment. Par conséquent, au moment de travailler avec les mégadonnées, il conviendra de se concentrer sur le problème à résoudre pour déterminer si la complexité et le coût qu’elles occasionnent sont compensés par la valeur commerciale qu’elles peuvent apporter.
L’analyse prédictive est le processus qui consiste à tirer des renseignements des données historiques afin d’effectuer des prévisions quant à des événements futurs. On a souvent recours à des techniques ancrées dans les statistiques pour approximer les relations entre un résultat cible et une série de variables explicatives. Cela permet aux scientifiques des données et aux actuaires d’appliquer ces relations à de nouveaux ensembles de données afin de faire des prédictions et d’établir des prévisions.
Pour la profession actuarielle, qui existe depuis plus de 100 ans, l’application de l’analyse prédictive est très familière, en particulier pour résoudre les problèmes liés aux « mégadonnées du passé ». Les actuaires jonglaient avec des milliers, voire des millions, d’incidents de mortalité, de santé ou de réclamations d’accidents pour extraire des renseignements au sujet des risques connexes. Ces données, les « mégadonnées du passé », auraient été bien difficiles à traiter et à accumuler avec les capacités informatiques de l’époque.
Néanmoins, les actuaires sont parvenus à surmonter ces difficultés grâce à l’innovation, tout comme les avancées informatiques nous permettent aujourd’hui de relever les défis associés aux mégadonnées.
Des approches différentes
Si les actuaires ont toujours eu recours à l’analyse prédictive pour concevoir les régimes de tarification ou pour évaluer les courbes de taux de mortalité, ils ont tendance à rechercher l’explicabilité dans les modèles et à opter pour des solutions explicites. Par ailleurs, les scientifiques des données, dont le travail vise l’exactitude des prédictions, préfèrent les approches algorithmiques telles que les modèles de renforcement du gradient (gradient boosted models) ou les modèles de réseaux de neurones (neural network models) en raison du meilleur rendement qu’elles offrent.
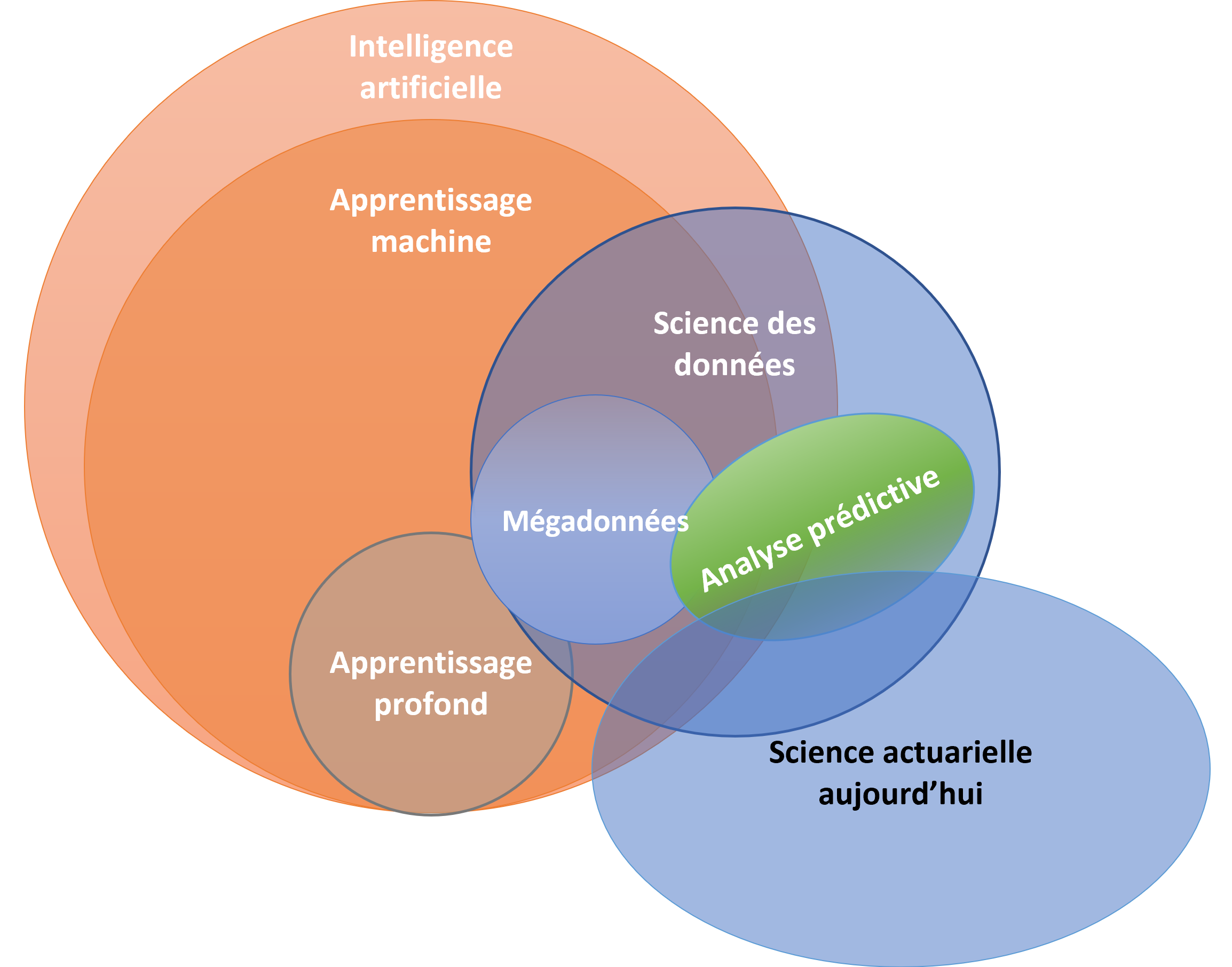
Ces exemples, ainsi que le diagramme de Venn, permettent de mieux illustrer la place qu’occupent les mégadonnées et l’analyse prédictive dans le travail actuariel. Grâce à l’augmentation des développements technologiques, les actuaires ont davantage d’occasions de tirer profit des mégadonnées pour parfaire leur travail. En appliquant l’analyse prédictive aux données télématiques elles-mêmes ou en travaillant en collaboration avec des scientifiques des données, les actuaires peuvent en faire beaucoup plus pour améliorer la prédiction et la quantification des risques.
De nos jours, bon nombre de scientifiques de données investissent beaucoup d’efforts dans la recherche de moyens de faciliter l’explication des résultats des modèles complexes afin de mieux cerner leurs limites à l’égard de certaines anomalies des données. Cela permet de remédier aux lacunes associées au recours à des approches algorithmiques et de rendre ces dernières plus accessibles pour les actuaires. En fin de compte, lorsque nous appliquons des modèles ou que nous tirons parti du travail des autres, nous devrions toujours prendre en considération la pertinence d’utilisation et la faisabilité de la mise en œuvre.
Intelligence artificielle (IA), apprentissage machine et apprentissage profond?
Nous entendons couramment aujourd’hui les termes IA, apprentissage machine et apprentissage profond, qui sont parfois utilisés de manière interchangeable. La compréhension de ces termes pourrait permettre aux actuaires de mieux communiquer avec les scientifiques des données.
On pourrait considérer chacun de ces termes comme un domaine d’étude, chacun étant plus pointu que le précédent :
- L’IA est un terme large et global. On pourrait la définir comme étant la théorie et la conception de systèmes (informatiques) ayant la capacité d’accomplir des tâches qui nécessitent habituellement l’intelligence humaine. Elle englobe tout, de la reconnaissance visuelle et du langage à la prise de décision, à la traduction et à l’automatisation de tâches humaines.
- On définit l’apprentissage machine comme étant l’utilisation et la conception de systèmes informatiques qui ont la capacité d’apprendre et de s’adapter sans suivre des directives explicites, en ayant recours à des algorithmes et à des modèles statistiques pour détecter des tendances dans les données et en tirer des déductions.
- L’apprentissage profond est un type d’apprentissage machine qui recourt à de grands réseaux de neurones comportant plusieurs niveaux d’abstraction s’inspirant de la structure et du fonctionnement du cerveau humain. Ces algorithmes se spécialisent dans des tâches telles que la reconnaissance des images et le traitement automatique du langage naturel.
L’application de ces domaines d’étude est très vaste et va au-delà de la science des données et de la science actuarielle. Les percées de l’informatique quantique pourraient bientôt permettre les simulations et les algorithmes complexes auparavant limités par les opérations informatiques classiques. Les actuaires pourraient appliquer ces nouvelles techniques à la modélisation des risques et à la quantification de problèmes tels que la modélisation du capital économique, les tests de sensibilité dynamiques et l’optimisation de portefeuille.
En somme, bien qu’elle puisse sembler nouvelle et quelque peu inconnue, la science des données est moins différente que le veut notre perception. Les données et la technologie sont en évolution constante. En tant qu’adeptes de l’apprentissage continu, les actuaires devraient toujours être à l’affût des techniques innovantes qui contribuent à améliorer leur travail et à remettre les traditions en question.